Cos’è l’alfabetizzazione dei dati?
Prima di immergersi nel mondo della Data Literacy, è importante capire i due concetti fondamentali che ne costituiscono il fondamento: dati e alfabetizzazione.
Definition of Data:
A sequence of one or more symbols given meaning by specific act(s) of interpretation. Data can be analysed or used in an effort to gain knowledge or make decisions. Digital data is represented using the binary number system of ones (1) and zeros (0) as opposed to its analogue representation. Data consists also in facts or information that can be used for reporting, calculations, planning, or analysis.
Definition of Literacy:
The ability to read and write; Knowledge of a particular subject, or a particular type of knowledge.
Cos’è l’alfabetizzazione dei dati?
Secondo Raul Bhargava e Catherine D’ignazio del MIT e dell’Emerson College, la Data Literacy può essere definita come la capacità di leggere, operare, analizzare e discutere con i dati. Sebbene questa definizione metta in mostra un concetto relativamente semplice, assume una maggiore complessità nel mondo di oggi, sempre più digitale e connesso, dove l’informazione scorre tra tutte le sfere della vita ed è ampiamente accessibile via Internet.
Come tale, l’alfabetizzazione dei dati acquisisce in sé una serie di caratteristiche relative ai dati e aree di sub competenze che sono molte volte indicate da diversi autori. Si tratta di specificità flessibili, il che significa che possono variare da modello a modello e in contesti diversi. Di seguito, vi presentiamo almeno 2 distinti Data Literacy Frameworks in cui si nota questa flessibilità.
Watch this video before you continue: “What are Data and Data Literacy. Study Hall Data Literacy”
DigiComp 2.0
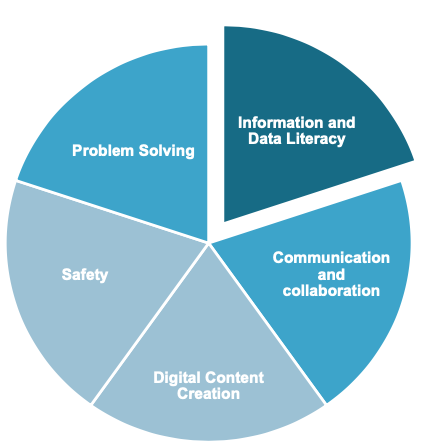
Il DigiComp 2.0 (The Digital Competence Framework 2.0) della Commissione europea identifica una serie di competenze digitali chiave per i cittadini europei. Una delle 5 aree principali incluse nel quadro è l’Information and Data Literacy, definita come:
Articolare i bisogni di informazione, localizzare e recuperare dati digitali, informazioni e contenuti. Giudicare la rilevanza della fonte e del suo contenuto. Conservare, gestire e organizzare dati, informazioni e contenuti digitali.
Download DigiComp 2.0 Framework for CItizens – Conceptual Reference Model here.Download DigiComp 2.0 Framework for CItizens – with examples here.
Secondo DigiComp 2.0, la Data Literacy comprende tre dimensioni di competenze: 1) Navigare, cercare e filtrare dati, informazioni e contenuti digitali; 2) Valutare dati, informazioni e contenuti digitali; 3) Gestire dati, informazioni e contenuti digitali. Queste tre sono descritte di seguito.
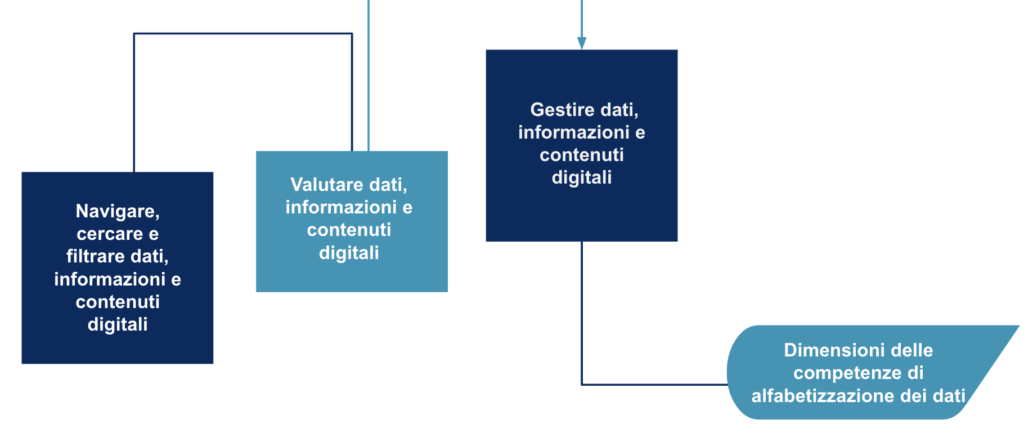
Navigare, cercare e filtrare dati, informazioni e contenuti digitali
- Articolare i bisogni di informazione, cercare dati, informazioni e contenuti in ambienti digitali, accedervi e navigare tra di essi. Creare e aggiornare strategie di ricerca personali.
Valutare dati, informazioni e contenuti digitali
- Analizzare, confrontare e valutare criticamente la credibilità e l’affidabilità delle fonti di dati, informazioni e contenuti digitali. Analizzare, interpretare e valutare criticamente i dati, le informazioni e i contenuti digitali.
Gestire dati, informazioni e contenuti digitali
- Organizzare, memorizzare e recuperare dati, informazioni e contenuti in ambienti digitali. Organizzare ed elaborare in un ambiente strutturato.
Cos’è l’alfabetizzazione dei dati? – Modello Qlik
Come spiegato, ci sono molti approcci diversi alla Data Literacy. Qlik presenta una definizione di Data Literacy che si basa sullo stesso punto di partenza comune: l’alfabetizzazione dei dati come la capacità di leggere, lavorare con, analizzare e discutere con i dati. I concetti all’interno della definizione sono quelli che sono considerati all’interno del suo framework Data Literacy, come si può vedere nell’immagine.
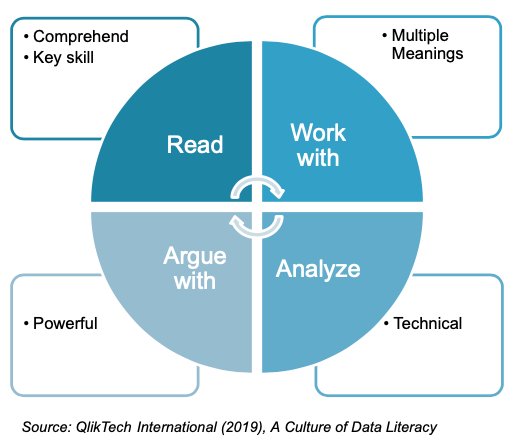
Il modello di Qlik non si limita a presentare un quadro di definizione di Data Literacy, ma si spinge oltre e indica le seguenti caratteristiche di data literacy che sono considerate fondamentali perché una persona o un’organizzazione possa considerarsi Data Literate:
- Data Fluency: utilizzare il linguaggio, il vocabolario e le abilità di conversazione legate all’alfabetizzazione dei dati;
- Abilità analitiche: utilizzare e sviluppare abilità di pensiero analitico, utilizzando tecniche adeguate di risoluzione dei problemi;
- Metodologie statistiche: La cultura dell’alfabetizzazione dei dati utilizza e abbraccia le statistiche all’interno dell’organizzazione;
Visualizzazioni dei dati: aiutano a semplificare i dati, consentendo a vari gruppi di competenze di assorbire e utilizzare i dati.
Source: QlikTech International (2019), A Culture of Data Literacy
Come diventare Data Literate?
All’interno di qualsiasi organizzazione, che sia un’università, un’azienda o un’associazione, è importante assicurarsi che le persone siano consapevoli della data literacy. Molte volte, le persone hanno bisogno di supporto per acquisire o migliorare le nozioni che le aiutano ad andare avanti e diventare Data Literate. Indipendentemente dal proprio ruolo (studente, insegnante, professionista, manager, leader, ricercatore direttore…) è fondamentale considerare quanto segue:
- Comprendere la definizione dell’organizzazione e la visualizzazione dei dati e l’alfabetizzazione dei dati;
- Non bisogna essere riluttanti a usare più dati nei propri compiti quotidiani;;
- Avere una mentalità della cultura dei dati.
- Cerca di identificarti con una delle quattro personalità di dati:
- Data Scientist;
- Data Champion;
- Data Dreamer;
- Data Doubter.
- Le persone a livello di top management di qualsiasi organizzazione dovrebbero incoraggiare la creazione e la realizzazione degli elementi citati.
Data Doubter
• Occorre mantenere l’equilibrio con chi dubita dei dati
– Aiutarli a vedere il “perché” dietro i dati
– Può essere una chiave per far crescere l’alfabetizzazione sui dati
– Aiutarli a progredire nelle loro competenze
DATA DREAMER
– Principianti nel mondo dei dati
– Incarnano l’essenza dell’alfabetizzazione sui dati
– Necessità di stabilire un forte ritmo di apprendimento
– Necessità di alimentare il loro desiderio di imparare
DATA CHAMPION
– Desideroso di imparare
– Necessità di continuare ad accrescere le competenze sui dati
– Aumentare l’uso dei dati
– Assicurare un apprendimento coerente
DATA SCIENTIST
– Ruolo cruciale
– Competenze statistiche
– Lavorare bene con i dati
– Mentori all’interno delle organizzazioni
Ruolo dei leader
I leader e i dirigenti di alto livello che hanno il potere di influenzare le strategie delle istituzioni hanno la responsabilità ultima di avviare e ottimizzare la Data Literacy tra i suoi dipendenti, studenti, insegnanti, personale, ecc.
A tal fine, KPMG ha creato un approccio di gestione del cambiamento comportamentale che può essere utilizzato per guidare e sostenere il processo di diventare Data Literate.
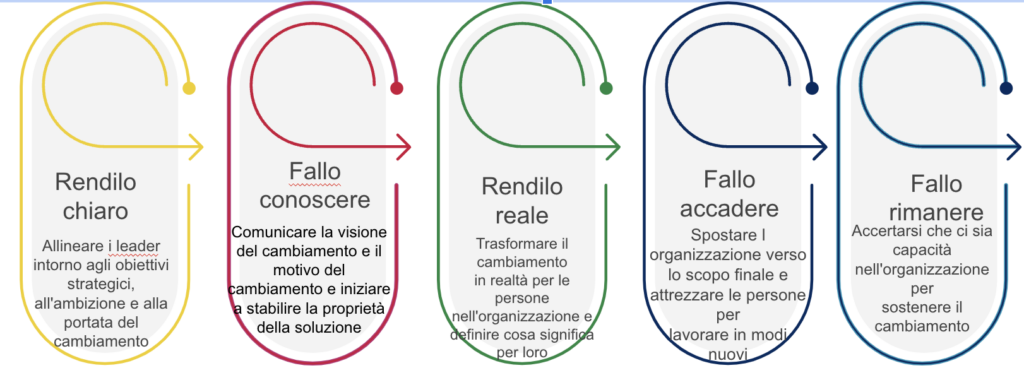
Concetti chiave dei dati
Affinché una persona diventi Data Literate, è molto importante capire alcune nozioni chiave fondamentali relative ai dati. I concetti che seguono aiuteranno a navigare e a capire meglio argomenti relativi ai dati:
- Dato: ogni singola informazione (come la temperatura alle 16:00 esatte di ieri) è un singolo dato, o datum.
- Dati: Tutte le informazioni messe insieme (come l’intera variazione di temperatura di ieri) sono dati, o informazioni specifiche che si raccolgono per prendere decisioni.
- Set di dati: collezioni di informazioni correlate.
- Variabili di dati o tipi di dati: particolari tipi di informazioni che possiamo usare per dividere un insieme di dati più grande.
- Censimento: informazioni da ogni membro di una popolazione
- Campione: una sotto-raccolta più piccola. È una porzione, una parte o una frazione dell’intero gruppo e agisce come un sottoinsieme della popolazione
Tendenza centrale: In statistica, una tendenza centrale (o misura della tendenza centrale) è un valore centrale o tipico per una distribuzione di probabilità. Può anche essere chiamato centro o posizione della distribuzione. Le tre misure principali della tendenza centrale sono: media; mediana; modalità
Tipi di dati
Comprendere i diversi tipi di dati (in statistica, ricerca di marketing o scienza dei dati) ti permette di scegliere il tipo di dati che più si avvicina alle tue esigenze e ai tuoi obiettivi.
Che tu sia un uomo d’affari, un marketer, uno scienziato di dati, uno studente o un altro professionista che lavora con alcuni tipi di dati, dovresti avere familiarità con la lista chiave dei tipi di dati.
Perché? Perché le varie classificazioni di dati vi permettono di utilizzare correttamente le misurazioni e quindi di prendere correttamente le decisioni.

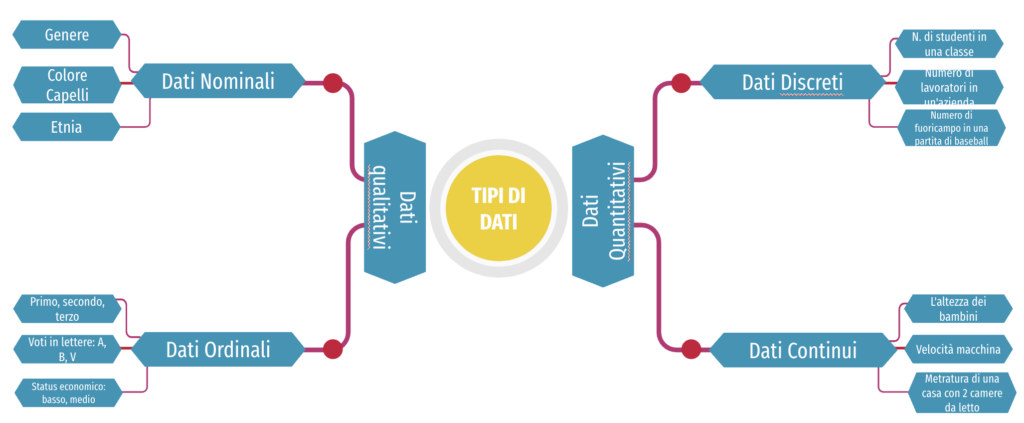
Dati quantitativi VS qualitativi
| Dati quantitativi |
| I dati quantitativi sembrano essere i più facili da spiegare. Risponde a domande chiave come “quanti, “quanto” e “quanto spesso”. I dati quantitativi possono essere espressi come un numero o possono essere quantificati. In parole povere, possono essere misurati da variabili numeriche. I dati quantitativi si prestano facilmente alla manipolazione statistica e possono essere rappresentati da un’ampia varietà di tipi di grafici e diagrammi statistici come la linea, il grafico a barre, lo scatter plot, ecc. Esempi di dati quantitativi: Punteggi in test ed esami, ad esempio 85, 67, 90 e così via. Il peso di una persona o di un oggetto. Il tuo numero di scarpe. La temperatura in una stanza. Ci sono 2 tipi generali di dati quantitativi: dati discreti e dati continui. |
| Dati Qualitativi |
| I dati qualitativi non possono essere espressi e misurati come un numero. I dati qualitativi sono costituiti da parole, immagini e simboli. I dati qualitativi sono anche chiamati dati categorici perché le informazioni possono essere ordinate per categoria. I dati qualitativi possono rispondere a domande come “come questo è successo” o “perché questo è successo”. Esempi di dati qualitativi: Colori, per esempio il colore del mare La tua destinazione preferita per le vacanze, come Hawaii, Nuova Zelanda, ecc. Nomi come John, Patricia,….. Etnia come indiani d’America, asiatici, ecc. Di più puoi vedere sul nostro post dati qualitativi vs dati quantitativi. Ci sono 2 tipi generali di dati qualitativi: dati nominali e dati ordinali. |
Dati nominali vs. ordinali
| Dati Nominali |
| I dati nominali sono usati solo per etichettare le variabili, senza alcun tipo di valore quantitativo. Il sostantivo ‘nominale’ deriva dalla parola latina “nomen” che significa ‘nome’. I dati nominali si limitano a nominare una cosa senza applicarla a un ordine. In realtà, i dati nominali potrebbero essere chiamati semplicemente “etichette”. Esempi di dati nominali: Genere (Donne, Uomini) Colore dei capelli (Biondo, Marrone, Brunetto, Rosso, ecc.) Stato civile (Sposato, Single, Vedovo) Etnia (Ispanico, Asiatico) Come vedete dagli esempi non c’è un ordine intrinseco delle variabili. Il colore degli occhi è una variabile nominale con alcune categorie (blu, verde, marrone) e non c’è modo di ordinare queste categorie dalla più alta alla più bassa |
| Dati Ordinali |
| I dati ordinali mostrano in che ordine si trova un numero. Questa è la differenza cruciale dai tipi di dati nominali. I dati ordinali sono dati che vengono messi in qualche tipo di ordine in base alla loro posizione su una scala. I dati ordinali possono indicare la superiorità. Tuttavia, non si può fare aritmetica con i numeri ordinali perché mostrano solo la sequenza. Le variabili ordinali sono considerate come una via di mezzo tra le variabili qualitative e quelle quantitative. In altre parole, i dati ordinali sono dati qualitativi per i quali i valori sono ordinati. In confronto ai dati nominali, i secondi sono dati qualitativi per i quali i valori non possono essere messi in un ordine. Possiamo anche assegnare dei numeri ai dati ordinali per mostrare la loro posizione relativa. Ma non possiamo fare matematica con questi numeri. Per esempio: “primo, secondo, terzo…ecc. Esempi di dati ordinali: La prima, la seconda e la terza persona in una gara. I voti in lettere: A, B, C, ecc. Quando un’azienda chiede a un cliente di valutare l’esperienza di vendita su una scala da 1 a 10. Stato economico: basso, medio e alto. |
Dati discreti vs. continui
| Dati discreti |
| Come abbiamo detto sopra, i dati discreti e continui sono i due tipi chiave di dati quantitativi. Nella statistica, nelle ricerche di marketing e nella scienza dei dati, molte decisioni dipendono dal fatto che i dati essenziali siano discreti o continui. I dati discreti sono un conteggio che riguarda solo i numeri interi. I valori discreti non possono essere suddivisi in parti. Per esempio, il numero di bambini in una classe è un dato discreto. Si possono contare individui interi. Non si possono contare 1,5 bambini. In altre parole, i dati discreti possono assumere solo certi valori. I dati variabili non possono essere divisi in parti più piccole. Ha un numero limitato di valori possibili, per esempio i giorni del mese. Esempi di dati discreti: Il numero di studenti in una classe. Il numero di lavoratori in un’azienda. Il numero di home run in una partita di baseball. Il numero di domande del test a cui hai risposto correttamente |
| Dati continui |
| I dati continui sono informazioni che potrebbero essere significativamente divise in livelli più sottili. Possono essere misurati su una scala o su un continuum e possono avere quasi tutti i valori numerici. Per esempio, potete misurare la vostra altezza su scale molto precise – metri, centimetri, millimetri e così via. Si possono registrare dati continui in tante misure diverse – larghezza, temperatura, tempo e così via. È qui che si trova la differenza cruciale rispetto ai tipi di dati discreti. Le variabili continue possono assumere qualsiasi valore tra due numeri. Per esempio, tra 50 e 72 pollici, ci sono letteralmente milioni di altezze possibili: 52,04762 pollici, 69,948376 pollici e così via. Una buona grande regola per definire se un dato è continuo o discreto è che se il punto di misura può essere ridotto a metà e ha ancora senso, il dato è continuo. Esempi di dati continui: La quantità di tempo richiesta per completare un progetto. L’altezza dei bambini. La metratura di una casa con due camere da letto. La velocità delle automobili. |